CS 4313 -- Spring 1997
Automata and Formal Language Theory
This course was an undergraduate elective in automata and formal
language theory. As I expected, the students didn't like the theory
all that much, and they really disliked the proofs. However, as with
most CS students, these students really wanted to write programs. For this
reason, I used a project that I had used before: writing a
recognizer for an arbitrary regular expression (RE).
This project is the main important part of the materials given
below. These are scans of notes because I no longer have
machine-readable copy.
Project: Regular Expression Recognizer:
- Project for 1992.
The first portion below (pages 4-8 of the first table) gives a description of
the project that I used in 1992. The remaining pages are some
of the rest of the materials for the 1992 course.
- Project for 1980. The second portion
(pages 1-12 of the second table) gives a more complete description that I used in 1980
for a graduate algorithms course (with relatively weak students).
This earlier description has notation that is slightly different from
the other, and is not as good.
- Using RPN as an intermediate form.
I had the students use a
parser (suggested was a simple recursive descent parser)
to translate the RE into reverse Polish form. This might seem
like a wholely unnecessary step (well, it is), but it helps
students (especially weaker ones), by separating off the parser
from the rest of the program. Many courses in automata and
formal language theory start with finite automata. With the
parser separated off, students could use RPN as input to the later
phases of the program. Then later in the semester, when they were studying
context-free grammars and their recognizers, the students could
add in the translator to RPN.
- Input to the program.
The program would take an input regular expression (RE) and an input
string. The program then recognizes the first occurrence
of a substring described by the regular expression.
The recognized string doesn't have to start at the start of
the input string nor does it need to end at the end of the
input string. (Students would append
.* at the beginning of the RE).
- Format of the REs. The regular expressions could
be arbitrarily complicated,
involving the operators concatenation, alternation, and star.
The "syntactic sugar" of REs in programming languages, such
as Perl, is not included as a requirement.
Symbols used in the 1992 program:
- A star * for the star operator.
- A plus + for concatenation.
Initially students would assume an explicit concatenation
operator which they would later drop.
Of course, normally + is just
the "one or more" operator, defined by
a+ = aa*,
but this project didn't implement this operator, since one can
easily get along without it.
- A vertical line | for the alternation
operator.
- Parentheses ( and )
for grouping.
- A dot . to represent an arbitrary
character.
- An at-sign @ representing the empty string
(usually not allowed in software REs).
- Other characters recognizing themselves.
- The special characters above can be handled by using backslash
(\) as an escape character
before the special character.
- Scope of the project. This project
is good for an undergraduate algorithms or automata course.
It was one of my all-time favorite projects, although I only
used it three times.
- Concepts needed.
- A parser for REs based on a formal grammar,
- RPN and the algorithm for evaluating RPN,
- representing an RE with an NFA with epsilon moves,
- computer representation and construction of an NFA,
- simulating the actions of an NFA in parallel on input
(includes epsilon closure). (This part helps students understand
the construction of a DFA from an NFA.)
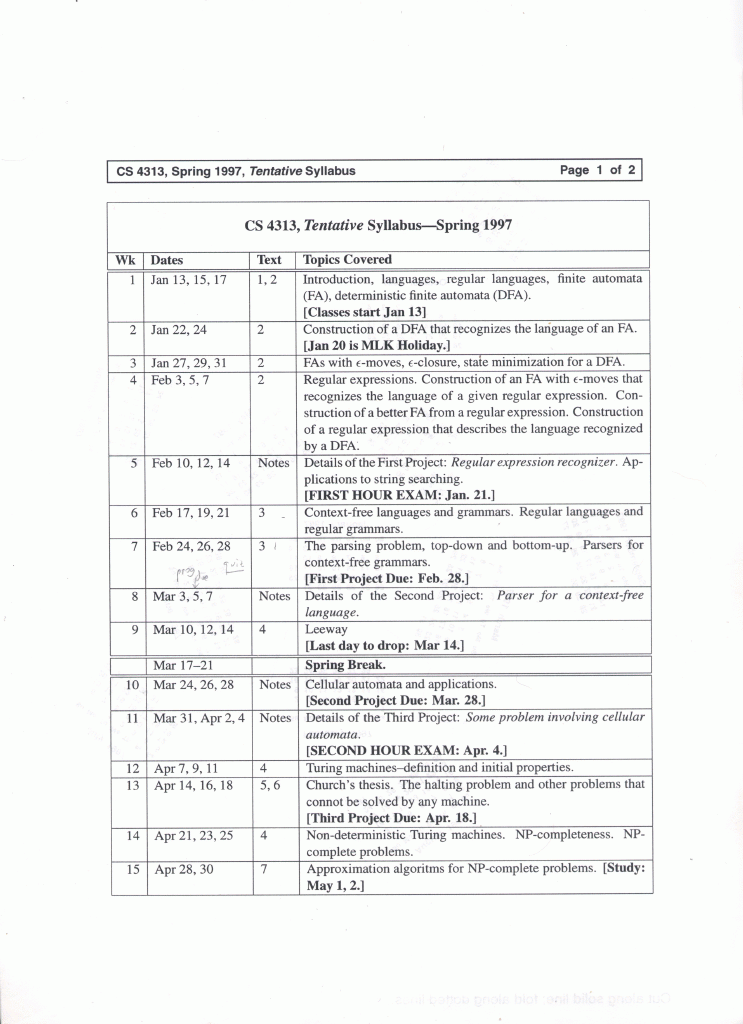
| Course Materials for 1992 |
|---|
| Section | Pages |
|---|
| Syllabus | Page 1:
small,
large
Page 2:
small,
large |
| Calendar | Page 3:
small,
large |
Regular
Expression
Recognizer | Page 4:
small,
large
Page 5:
small,
large
Page 6:
small,
large
Page 7:
small,
large
Page 8:
small,
large |
| Example | Page 9:
small,
large |
| Mid-term Exam | Page 10:
small,
large |
| Final Exam | Page 11:
small,
large
Page 12:
small,
large |
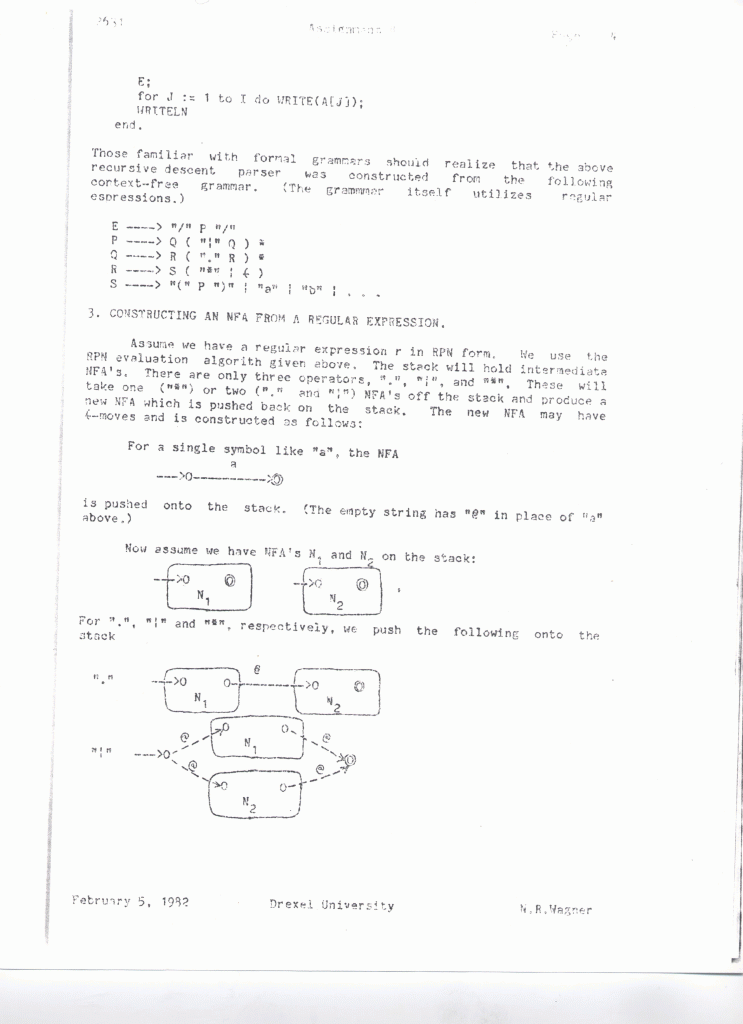
Here is the older (1982), and more detailed version
of the project to recognize regular expressions. Some of the notation
here was a bad choice, since I used a dot
.
for concatenation, rather than a plus, so that dot couldn't be
used for the "match any character" symbol.
| Project Materials for 1980 |
|---|
| Program | Pages |
|---|
Regular
Expression
Recognizer | Page 1:
small,
large
Page 2:
small,
large
Page 3:
small,
large
Page 4:
small,
large
Page 5:
small,
large
Page 6:
small,
large
Page 7:
small,
large
Page 8:
small,
large
Page 9:
small,
large
Page 10:
small,
large
Page 11:
small,
large
Page 12:
small,
large |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}