
CS 3723/3721
|
|
|
|
The main Ruby reference: In these notes and elsewhere my principal reference is
However, a new 2nd edition, with 50% more material (and extra author Chad Fowler), is available for sale at Amazon.com.
Here is a Ruby program from the PPG that resembles its counterpart in Perl. The program prints all lines in the input stream that contain the word "Ruby". Notice that while and if statements (along with most others) end with end and do not make use of {} blocks, as in Perl.
while gets # assigns each input line to $_ by default
if /Ruby/ # matches against $_ by default
print # prints $_ by default
end
end
Here is another version in Ruby about which PPG says: "The 'Ruby way" to write this would be to use an iterator" (a more general construct than in Perl):
ARGF.each { |line| print line if line =~ /Ruby/ }
PPG says: "This used the predefined object ARGF, which represents the input stream that can be read by a program."
% perl -e 'print 5+2; $x = "hi"; print $x,"\n";'
7hi
% ruby -e 'print 5+2; $x = "hi"; print $x,"\n";'
7hi
% ruby -e 'print 5.+(2); x=%q|hi|; print "#{x}\n"'
7hi
%Here the -e option on either Perl or Ruby causes the quoted string following to be treated as one line of program source to be interpreted. The first two inputs show that this is a program that both Perl and Ruby execute, both producing output 7hi. The third line is more "Ruby-like" and includes the strange features:
In Perl, the expression 5.+(2) is legal and just means to add floating point 5 and integer 2. For this reason, Ruby requires a digit after the decimal point of any floating point constant, since otherwise 5.+(2) would be ambiguous in Ruby.
In a similar way, for many of Ruby's constructs, such as the if-then-else-end or the while-do-end, a keyword at the end of a line, such as then or do is optional and usually omitted. (This is also illustrated in the program above.)
| Ruby example showing arrays |
|---|
#!/usr/local/bin/ruby
x = 3
a = [14, 3.1415926, 'kitty', "Tell me #{x} times", [2, 3, 4]]
print a[3] # Prints: Tell me 3 times
a[1, 2] # [3.1415926, 'kitty']
a[4] # [2, 3, 4]
print a[4][1] # prints: 3
b = Array.new(5, "A") # b is ["A", "A", "A", "A", "A"]
b[3] = 13 # b is ["A", "A", "A", 13, "A"]
b[6] = 8 # b is ["A", "A", "A", 13, "A", nil, 8]
b.each {|x| print x, " "} # prints: A A A 13 A nil 8
print b.length # prints: 7
print b[-1] # prints: 8, the last element
print b[-4] # prints: 13, 4 back from last element
c = Array.new # new empty array
print c.length # prints: 0
c[2] = 47
for x in 0...c.length # prints: nil nil 47
print c[x], " "
end
for x in 0...c.length do print c[x], " " end # same thing
m = %w( Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec )
m.each {|x| print x, " "} # prints: Jan Feb Mar Apr ...
m.collect! {|x| x.downcase + ':'} # applies {} block to each element of m
# downcase turns caps in a string to lowercase
m.each {|x| print x, " "} # prints: jan: feb: mar: apr: ...
|
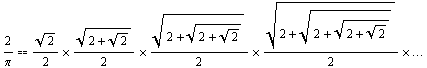
Notice the statement require "math2" at the beginning of the program to use the sqrt2 function, which makes the class containing the function available to the other program. The code resembles Java.
Notice also that the way the middle function is structured, the variable m cannot be a local variable inside the function pi, but, if it's not a parameter, it must be global, and so must be written as $m.
The file math2.rb could have consisted of just the definition of the function sqrt2, not embedded in a class. Then in the file piproduct.rb, the code could just use the function sqrt2 directly without instantiating a class and without the variable $m.
| Code for sqrt
function File: math2.rb |
Code to calculate pi File: piproduct.rb |
Output of run (parameter on command line) |
|---|---|---|
#!/usr/local/bin/ruby
class Math2
def sqrt2(x)
x = x.to_f # to float
if x < 0 # if undefined
nil
elsif x == 0 # sqrt(0) = 0
0.0
else
# use better init value
y = x
# use Newton's method
yold = y + 1.0
while (y-yold).abs >
0.1e-14
yold, y =
y, x/(2*y) + y/2
end
y # return answer
end
end
end
|
#!/usr/local/bin/ruby
require "math2"
def pi(n)
p = 2 # final product
b = 0 # each denom
for i in 1..n
b = $m.sqrt2(2 + b)
t = 2.0/b # term
p *= t
if i%2 == 0
print " i: ", i,
", t: ", t,
", p: ", p, "\n"
end
end
p
end
$m = Math2.new
x = ARGV[0].to_i
print "pi: ", pi(x), "\n"
|
% piproduct.rb 25
i: 2, t: 1.08239220029239
p: 3.06146745892072
i: 4, t: 1.00483857237631
p: 3.13654849054594
i: 6, t: 1.0003012720413
p: 3.14127725093277
i: 8, t: 1.00001882507178
p: 3.14157294036709
i: 10, t: 1.00000117654968
p: 3.1415914215112
i: 12, t: 1.00000007353429
p: 3.14159257658487
i: 14, t: 1.00000000459589
p: 3.14159264877699
i: 16, t: 1.00000000028724
p: 3.14159265328899
i: 18, t: 1.00000000001795
p: 3.14159265357099
i: 20, t: 1.00000000000112
p: 3.14159265358862
i: 22, t: 1.00000000000007
p: 3.14159265358972
i: 24, t: 1
p: 3.14159265358979
pi: 3.14159265358979
|
This section studies regular expressions in Ruby, with emphasis on how Ruby's REs are object-oriented. The section assumes a knowledge of REs that one might get from the systems programming course. To quote from the PPG,
"... when Matz designed Ruby, he produced a fully object-oriented regular expression handling system. He then made it look familiar to Perl programmers by wrapping all these $-variables on top of it."
| Illustrating Ruby
Regular Expressions File: re.rb |
|---|
#!/usr/local/bin/ruby
re = /(\d+):(\d+)/ # match a time hh:mm
re.class # yields: Regexp
md = re.match("Time: 12:34am")
md.class # yields: MatchData
md[0] # == $&, yields: "12:34"
md[1] # == $1, yields: "12"
md[2] # == $2, yields: "34"
md.pre_match # == $`, yields: "Time: "
md.post_match # == $', yields: "am"
# now do more matching
md1 = re.match("Time: 11:47am")
md2 = re.match("Time: 10:30pm")
md1[1, 2] # yields: ["11", "47"]
md2[1, 2] # yields: ["10", "30"]
|
The main example in this section gives a Ruby program that translates a file of data I get from the UTSA system for each course. The "before" and "after" for each line looks as follows. (Actually, I would probably leave the initial name the same, but I'm trying to illustrate REs here.)
Old Line: 19 Kartaltepe, Erhan J. @00777777 **Web Registered (extra stuff) ... New Line: <li>Erhan J. Kartaltepe, Email: ekartalt@cs.utsa.edu
The RE: /^(\d+)\s+([-a-zA-Z]+),\s+(.+)(@\d+)\s+.*$/ is designed for the "old" lines:
| Matches in the example RE | |
|---|---|
| RE portion | Meaning |
| ^ | start of line |
| (\d+) | one or more digits, Match 1 (unused) |
| \s+ | one or more whitespace chars |
| ([-a-zA-Z]+) | one or more letters (or a hyphen), Match 2 |
| , | a comma |
| \s+ | one of more whitespace chars |
| (.+) | one or more of any chars up to '@', Match 3 |
| (@\d+) | '@', plus one or more digits, Match 4 (unused) |
| \s+ | one or more whitespace chars |
| .* | anything at all |
| $ | end of the line |
Here is the Ruby program that does the translation. The program makes no use of the Perl style "$" variables. Also, since there are three matches active at the same time, this example uses the fact that one can get the matching characters of all three matches at the same time, something not possible in Perl. (In Perl, the "$" variables would overwrite one another. Of course this is not a real "problem", and you can easily get around it in Perl.) The third match is artificial, just to try out another match, since it just picks off the first character in the string. Even though this example makes use of Ruby's capabilities, it would be easy to structure it into simple Perl.
| File Translation Using a
Regular Expression File: rexp.rb |
|---|
#!/usr/local/bin/ruby
print "<ol type=1>\n"
while line = gets # fetch next line of input file
re = /^(\d+)\s+([-a-zA-Z]+),\s+(.+)(@\d+)\s+.*$/ # main RE
m = re.match(line) # match line with RE
re2 = /[a-zA-Z]{1,7}/ # a 2nd RE: at least 1 and at most 7 letters
m2 = re2.match(m[2]) # match portion of 1st match with 2nd RE
re3 = /^([A-Z])/ # a 3rd RE: a single initial uppercase letter
m3 = re3.match(m[3]) # match portion of 1st match with 3rd RE
# output new altered line
# strip removes initial and terminal whitespace from a string
newline = "<li>" + m[3].strip + " " + m[2] + ", " +
"Email: " + (m3[1] + m2[0]).downcase + "@cs.utsa.edu\n"
print newline
end
print "</ol>\n"
|
Here are the input and output files: input file (text), output file (text), output file (HTML),
This section studies classes. [Under construction, but read the link above.]