|
| CS 3723
Programming Languages |
Lexical Analysis
(Scanning) |
[First look at Compiler Overview.]
Lexical Analysis or Scanning:
The first stage of a compiler uses a
scanner or lexical analyzer to do the following:
- Break the source program into a sequence of basic unit
called tokens.
- Use a convenient coded internal form for each token.
- For some tokens, such as identifiers, keywords,
and constants,
return a code for the type of token along with a pointer into
a table for the specific token.
- Recognize and discard comment.
- Keep track of source code line numbers.
- Discard whitespace.
- Take care of machine dependent anomalies.
The different types of tokens recognized are
the following (with a lot of variation in different languages):
- identifier: This is usually defined as an initial
letter, followed by any sequence of letters or digits.
The formal definition often includes other possibilities,
such as an underscore character ( _ ) in the same
places where a letter can occur.
- keyword or reserved word: Certain strings of letters
would look just like an identifier, but are actually used as
a keyword in the language and cannot be used as an identifier.
- constant: Depending on the language, there are
a number of different types of constants: integer, floating point,
boolean, string, character, and others.
- operator: Operators are usually one or two special
characters. They are also usually infix, prefix, or postfix.
C and C++ have the operator sizeof, and C++ also has
operators new and delete.
More complex operators exist,
such as the infamous ternary operator ? :
(present in C, C++, Java, and even Ruby, and
treated by the scanner as separate tokens).
- special character: A number of special characters
are used to separate other tokens from one another,
such as
( ) [ ] { } : ; , . Characters are also used for many
special purposes, depending on the language.
In addition there are lexical conventions that can sometimes
be quite complicated. For example, so-called whitespace
characters are normally used just to separate tokens.
Tokens such as keywords or identifiers need to be separated
from one another, while others such as special characters don't
need to be separated from anything. As a programmer, you know
this more-or-less, but for someone writing a scanner these rules
need to be precisely defined.
Even comments in "traditional" languages can be confusing
and complex. For example, a newline (\n) can be embedded
in a /* ... */-style comment, but a //-style
comment must end with a newline. What value does the following
assign to x ? Is it
3 or 1.5 or 0.75? Or is it an error?
Scanners are dumb and not too hard to write:
Any sequence of tokens at all
is OK by the scanner as long as they are properly separated.
Between any two tokens, there can always be any number of whitespace tokens.
The scanner doesn't put out many error messages by itself.
Python is a special case:
The block structure of a language is almost always unraveled by
the phase after the scanner: syntax analysis, performed by the parser.
Python is unique among languages in that its block structure must be
determined using special processing by the scanner.
In Python the block structure is dictated by the amount of
(whitespace, usually blanks) indentation. In the C program below,
the block structure is implicit in the use of {} braces.
The parser (= syntax analyzer) will determine the block structure.
Python uses the scanner for this,
Example (from C):
The C program fragment below
for (i=0; i <= num; i++) {
ch = alf[i];
printf("ch: %c", ch);
} |
produces the following sequence of tokens:
As mentioned above, this is the sequence of tokens that is produced, but
the actual tokens don't look like this. In each case, the kind of token
is represented by an internal code. In some cases (identifier, keyword,
constant), the token is accompanied by a pointer (or reference) into
some table.
Recognizing tokens with an FSM:
The most common way to separate out the tokens is to first
write a finite state machine (FSM) that describes each token.
Then the FSM is converted to a program, either by hand or using
a automated software tool to produce the program
(such as lex or flex or others in unix; even Java
has library stuff to produce a scanner).
The FSM approach is formally equivalent to using a
regular expression to recognize tokens. We'll use a
write-by-hand approach in a simple scanner program (in Homework 2,
to recognize a double).
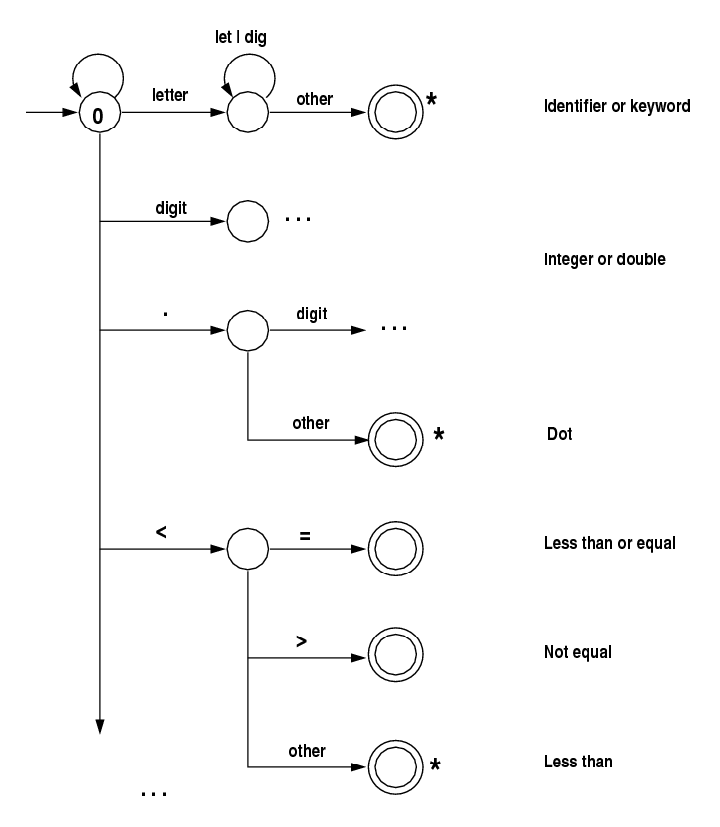 Notes:
Notes:
- The diagram above shows just the start of the desired FSM.
- The scanner always uses the next non-whitespace char
to decide what to do. Above, decisions are given in case the
first char is a letter, a digit, a dot, <, or (.
- The scanner always peeks ahead one additional char.
Sometimes the token is known without looking ahead.
Above, the tokens .,
(,
<=, and
<>
are known, regardless of the next char. In case the
next char must be examined to be sure about the token,
the diagram above uses a *. This is just notation,
saying that the most recently read char should be pushed
back into input (ungetc() in C). Alternatively,
the scanner can always read the next char, whether it needs to or not.
- The scanner program starts in state 0. After it recognizes
a token, it goes back to state 0 again to get the next token.
[Another, more formal treatment of lexical analysis:
here.
Python tokenizer, written in C:
here.]
(Revision date: 2014-08-20.
(Please use ISO
8601, the International Standard.)
|