|
|
CS 3723 Programming Languages |
Finite Automata | |
- a finite set of states, each represented by a circle, with the name of the state inside. We will usually use successive integers starting with 0 as names, but the name can be anything.
- a finite set of transitions from state to state, each represented by an arrow going from state to state. A transition can go from a state to itself. The transition arrows are labeled with one or more symbols. The transition arrows are followed as input symbols for the alphabet are processed. The input symbol must match the label on the transition.
- One state (never more than one) must be designated the start state or initial state. This state is identified by an arrow with no start, but ending at the state.
- Any number of states (but at least one) must be designated the terminal states or final states or accepting states. These are identified using a double circle. The start state can also be a terminal state.
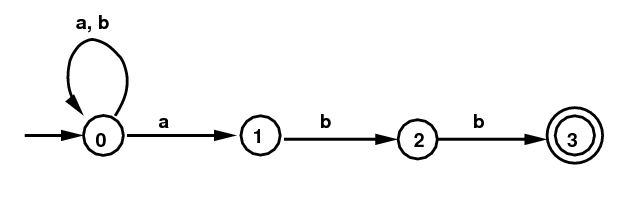
NFA for the RE (a|b)*abb
- NFAs.
The particular FA above is called a
Non-Deterministic Finite Automaton (NFA).
This NFA is said to recognize the language L above
(the one described by the RE (a|b)*abb.)
In order to recognize strings from L with the NFA above, we
process an input string character-at-a-time, starting with the
0th character, and starting at the start state 0. As
you read each character, it is processed by following
an arrow labeled with that character.
If we can manage (somehow, in any way) to end up in the
terminal state 3 just
as we finish all the characters in the string, we accept
the string as belonging to L. Otherwise we reject
the string.
This automaton is called non-deterministic because there
is a case (there must be at least one, or else it would be called
a DFA; see below)
with two or more possible choices for the arrow to take.
Suppose we are processing the symbol a in
the string "abaabbaabb". How
do we know when to leave state 0 and finish the string?
(We could decide with a look-ahead buffer, but we want a simpler
solution.)
- DFAs
Given an NFA, it is always possible to create what is
called a Deterministic Finite Automaton
(DFA) that recognizes the same language.
For the language L above, here is the corresponding DFA:
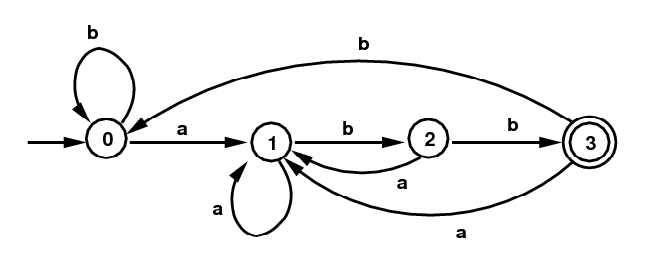
DFA for (a|b)*abbWe'll also call an automaton a DFA in case there is at most one choice for which arrow to follow. In case there is an input symbol and no choice of arrow to follow, this is considered an error. We can add an extra error state and add a transition to the error state in case there was no choice.