 |
CS 3723 Programming Languages |
Finite Automata | |
Languages: Start with a finite set of symbols called an alphabet, such as {0, 1}, or {a, b, c, d}, or the set of all Ascii characters. A finite string of these symbols is called a sentence. A language is a set of sentences. Thus a language is just some set of strings of symbols. For example, the set E of all strings of 0s and 1s with an even number of 1s is a language. (E = even parity bit-strings.) Notice that everything is finite except for the language, where in the interesting cases there are infinitely many sentences, as with the example above. We want to give finite descriptions of languages, including infinite languages. Consider another example: the set L of all strings of as and bs that end with "abb". The previous (English) sentence is an informal finite description. It would (of course) be impossible to list the elements of this language, but we could start: L = {abb, aabb, babb, aaabb, ababb, baabb, bbabb, aaaabb, aababb, ...}. The language L can be described or generated by the regular expression (a|b)*abb. If Σ denotes the alphabet, then (using regular expression notation), Σ* denotes the set of all finite strings of symbols from the alphabet. This includes the empty string "", which is denoted by the lower-case Greek letter epsilon = ε. Thus any subset of Σ* is a language. (In particular, the sets Σ* of all finite strings, and the empty set Ø of no strings are languages.)
Finite Automata (FA) (singular: "finite automaton"): These are also called Finite State Machines (FSM). An FA consists of a finite set of states and finite set of transitions from state to state that occur as input symbols for the alphabet are processed. A transition can go from a state to itself. One state (never more than one) must be designated the start state or initial state. Any number of states (but at least one) must be designated the terminal states or final states or accepting states. Here is a diagram of an FA:
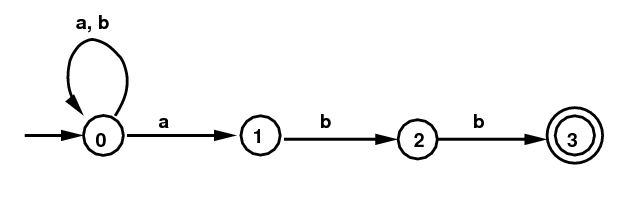
NFA for (a|b)*abb
- NFAs. The particular FA above is called a Non-Deterministic Finite Automaton (NFA). This NFA is said to recognize the language L above. In order to recognize strings from L with the NFA above, we process an input string character-at-a-time, starting with the 0th character. Start with the start state 0. For each character processed, follow a path labeled with that character. If we can manage (somehow) to end up in the terminal state 3 just as we finish all the characters in the string, we accept the string as belonging to L. Otherwise we reject the string. This automaton is called non-deterministic because there is a case (there must be at least one) with two possible choices for the arrow to take. Suppose we are processing the symbol a in the string "abaabaabb". How do we know when to leave state 0 and finish the string? (We could decide with a look-ahead buffer, but we want a simpler solution.)
- DFAs
Given an NFA, it is always possible to create what is
called a Deterministic Finite Automaton
(DFA) that recognizes the same language.
For the language L above, here is the corresponding DFA:
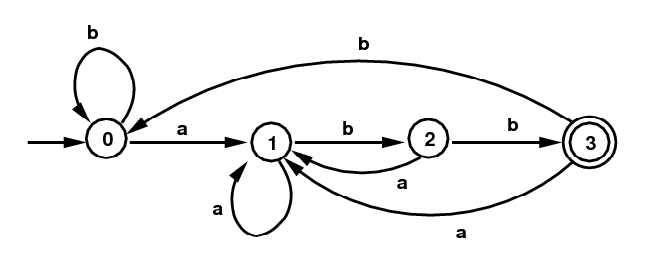
DFA for (a|b)*abb
Revision date: 2013-06-07. (Please use ISO 8601, the International Standard.)