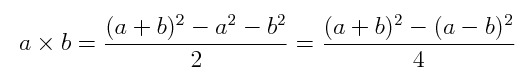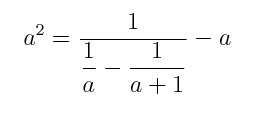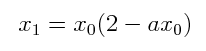|
| (Textbook. Click for information.) |
Analysis of Algorithms
Spring 2012
Recitation 12
Hashing, Reductions
Partial Answers
|
CS 3343/3341 Analysis of Algorithms Spring 2012 Recitation 12 Hashing, Reductions Partial Answers |
(Informal version) First check that the vertices listed in the "Cycle" column include every vertex exactly once. Second, check that each vertex in the "Cycle" column also appears in the same row under "Edges". Then it has to be a Hamiltonial cycle. |
// more formal version
boolean isHamilton(int[] Vertex, list[] Edges, int[] Cycle) {
int[] visited = new int[20];
set each visited[i] = 0;
for (i = 0 to 19) {
if (cycle[i] is not in the list Edges[i]) return false;
if (visited[cycle[i]] == 1) return false;
else visited[cycle[i]] = 1;
}
return true;
}
|
It is easier to calculate the probability that among
n people, no two have the same
birthday. Denote this by N(n).
For two people, the second one will have a birthday different
from the first with probability:
N(2) = 364/365.
If there is a third person
the probability that he will have a birthday different from
the first two (which are assumed distinct now),
is 363/365, so that
N(3) = (364/365)*(363/365).
Similarly,
N(4) = (364/365)*(363/365)*(362/365).
Of course, N(1) = 1.
The probability, call it S(n), that at least two
people from among n have the same birthday
is just:
S(n) = 1 - N(n).
Write a simple program that will calculate and print S(n) for n = 1, 2, 3, ..., 50. These should be calculated as doubles.
#include <stdio.h>
int main(){
double N[51];
N[1] = 1;
int i;
for (i = 2; i <= 50; i++) {
N[i] = N[i-1]*(365.-i+1)/365.;
printf("S(%i) = %10.8f\n",
i, 1 - N[i]);
}
}
S(2) = 0.00273973
S(3) = 0.00820417
S(4) = 0.01635591
S(5) = 0.02713557
S(6) = 0.04046248
S(7) = 0.05623570
S(8) = 0.07433529
S(9) = 0.09462383
S(10) = 0.11694818
| S(11) = 0.14114138 S(12) = 0.16702479 S(13) = 0.19441028 S(14) = 0.22310251 S(15) = 0.25290132 S(16) = 0.28360401 S(17) = 0.31500767 S(18) = 0.34691142 S(19) = 0.37911853 S(20) = 0.41143838 S(21) = 0.44368834 S(22) = 0.47569531 S(23) = 0.50729723 S(24) = 0.53834426 S(25) = 0.56869970 S(26) = 0.59824082 S(27) = 0.62685928 S(28) = 0.65446147 S(29) = 0.68096854 S(30) = 0.70631624 | S(31) = 0.73045463 S(32) = 0.75334753 S(33) = 0.77497185 S(34) = 0.79531686 S(35) = 0.81438324 S(36) = 0.83218211 S(37) = 0.84873401 S(38) = 0.86406782 S(39) = 0.87821966 S(40) = 0.89123181 S(41) = 0.90315161 S(42) = 0.91403047 S(43) = 0.92392286 S(44) = 0.93288537 S(45) = 0.94097590 S(46) = 0.94825284 S(47) = 0.95477440 S(48) = 0.96059797 S(49) = 0.96577961 S(50) = 0.97037358 |