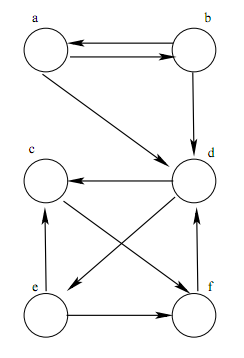
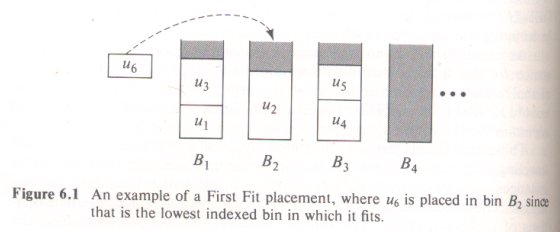
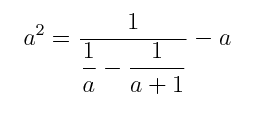- (25) Breadth-First and Depth-First Searches of Graphs: By hand, run through a BFS and a DFS for the graph below, starting with vertex a. Assume that vertices are ordered alphabetically in the adjacency lists. Show the vertices in the order that they are visited. For each search you must use a stack or a queue, whichever is appropriate, but should not use recursion for this problem. For each search and at each step you must show the contents of the stack or the queue.